| <HOME <お願い事項 <Access2002 TOP <Access2000 TOP <サイト内検索 | ||
| Access97データベース工作室>郵便番号の検索 | ||
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
これは、このクエリーの「結合の仕方」に左右されているものと思われます。
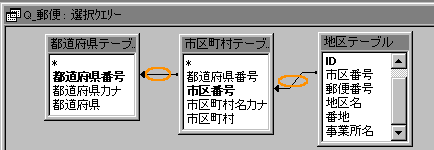
ちゃんとコード化されてるはずなんで、そんなことはありえないと思うんですけどね。
たまに・・・特に手書きのデータからよっこいしょと起こしたテーブルの場合なんかは、[市区町村テーブル]にない[市区番号]をうっかり地区テーブルの方に入力しちゃってたりしたら、片方にないんですから、でないですよね。
こういうことを防ぐためにも、リレーションシップってきっちり考えておかないといけないんですけども・・・。
外からインポートしてきたデータは、こういうの無頓着だったりしますもんね。
こういうときは、無頓着なデータに文句いってもらちがあかないんで、とにかくどういう形で結果が出れば一番処理に影響がないのか、じっくり考えましょう。
この場合、[地区テーブル]に郵便番号ががっさり入ってるわけですよね。
と、いうことは、[地区テーブル]中心で考えないといけないんじゃないでしょうか。どうでしょう。
おそらく、想像するに、[地区テーブル]の中に3レコード、[市区町村テーブル]に存在しない[市区番号]を使ってるレコードがあるんでしょう。
あるいは[市区番号]が空欄のレコードとか・・・。入力し忘れちゃったのかもしれないですね。
14万件ありますからねぇ・・・。
とりあえず、クエリーの結合パターンを見てみましょう。
テーブル間の結合線のところをダブルクリックしてみましょう。
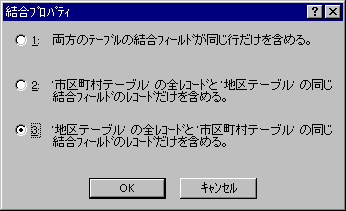
上の図でいくと、オレンジ色のところあたりを、強い意志を持ってきっぱりクリックします。
すると、←こんな感じの画面が出てきます。
フツウは、両方のテーブルに存在する値だけが対象となるわけですね。
<↓ふつうの結合:両方のテーブルの結合フィールドが同じ行だけを含める>
【テーブル1】 【テーブル2】 【ふたつを結合したクエリー】
社員番号 社員名 01 うみうし 02 いそぎんちゃく 03 はまぐり 06 たこ −
社員番号 社員名 01 うみうし 02 いそぎんちゃく 04 うつぼ 05 ひとで 06 たこ
社員番号 社員名 01 うみうし 02 いそぎんちゃく 04 うつぼ 06 たこ
<↓テーブル2の全レコードと、テーブル1の同じ結合フィールドだけ含める>
【テーブル1】 【テーブル2】 【ふたつを結合したクエリー】
社員番号 社員名 01 うみうし 02 いそぎんちゃく 03 はまぐり 06 たこ −
社員番号 社員名 01 うみうし 02 いそぎんちゃく 04 うつぼ 05 ひとで 06 たこ
社員番号 社員名 01 うみうし 02 いそぎんちゃく 04 うつぼ 05 ひとで 06 たこ
<↓テーブル1の全レコードと、テーブル2の同じ結合フィールドだけ含める。>
【テーブル1】 【テーブル2】 【ふたつを結合したクエリー】
社員番号 社員名 01 うみうし 02 いそぎんちゃく 03 はまぐり 06 たこ −
社員番号 社員名 01 うみうし 02 いそぎんちゃく 04 うつぼ 05 ひとで 06 たこ
社員番号 社員名 01 うみうし 02 いそぎんちゃく 03 はまぐり 06 たこ
と、いう感じで、どの結合プロパティを選ぶかによって、結果が多少変る可能性があるってわけなんですね。
ほんとうはキチントすべてのレコードがコード化されていて、[市区町村テーブル]に存在しない[市区番号]なんてありえないぞ、と強い態度に出ることができればいいんですけど、こりゃあたしの一存じゃチョット・・・。そこで、[地区テーブル]主体にものを考えて、[地区テーブル]すべてのレコードと、それに対応する[市区町村テーブル]のレコード、とうい結合パターンを選んでみました。
テーブル3つ以上の結合の場合、結合線は2本以上になりますよね。
かたっぽだけ結合プロパティを設定して、かたっぽノーマルというわけにはいかないんです。
[都道府県テーブル]と[市区町村テーブル]の間の結合線も、多い方に合わせる・・・つまり[市区町村テーブル]主体の結合に変更します。
矢印の向きが一定方向になってます?
今度は、[地区テーブル]の全レコード件数である140537件、出てきたはずです。いかがでしょう。
状況によっては、どっちかのテーブルよりの結合にした方がよい場合も、ありそうですよね。
で、[地区テーブル]にあるのに、[市区町村テーブル]にない[市区番号]を調べるためには・・・・。
不一致クエリーというやつがいいでしょう。
ウィザードを使って簡単に作れます。
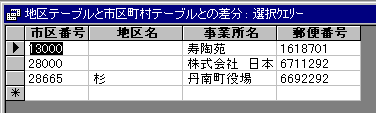
地区テーブルを基に、市区町村テーブルと比較して、[市区番号]で結び付ければ、答えは出ます。
出したところで、今回はどうしようもないんですけどね。
主キーとは、対外的にもかなり重要な役割を果たすんですね。
本来はオートナンバーで自動的に割り振った数字などではなく、きちんとそのレコードの代表選手としてテーブルの中で重要な役割を担うフィールドが望ましいのですが、なかなかそうはいかない場合もあるんです。
[地区テーブル]は、インポート時に作ったIDというフィールドを主キーにしています。では、[郵便番号]は、このテーブルの主キーにはなりえないんでしょうか。
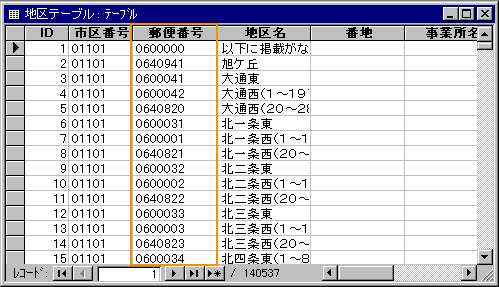
このテーブルの中に、同じ郵便番号を持つレコードが複数あったらアウトですよね。
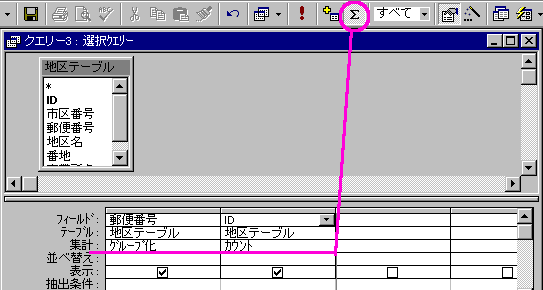
重複してるかどうか調べてみましょう。これはちょっとばかり集計クエリー(Σ)を応用します。
[地区テーブル]を基に、クエリーを作ります。
[郵便番号]と、他になんか適当なフィールドをひとつ選んで、ツールバーのΣボタンをクリックします。
すると、今までなかった「集計」という欄が現れます。[郵便番号]をグループ化、その他に選んだフィールドをカウントします。]
で、データシートビューに切り替えると、こんな感じのクエリー結果になります。
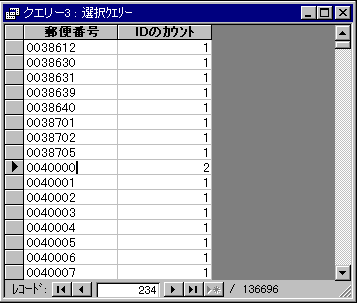
[郵便番号]が同じものどうしでグループにして、そのグループの中に属するレコードの数を数えてるんです。
まあ、同じ郵便番号のレコードはたいがい1件でしょうから・・・。
カウントっていったって、1件ずつですよね。
でも、レコード件数を見てください。
136696件。[地区テーブル]は140537件ありましたよね。
明らかに同じ郵便番号のレコードが複数あるってことです。
うーん、しかし、これを全部探し当てるのは・・・。
そこで、クエリーをこんな風に書き換えます。
カウント結果はほとんど1件ずつですが、この数が2以上の郵便番号だけ抽出できれば、多少目的は達成できますよね。
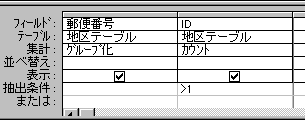
>1
1を超えた数だったら、ってことで、整数なら2以上と考えて差し支えないでしょう。
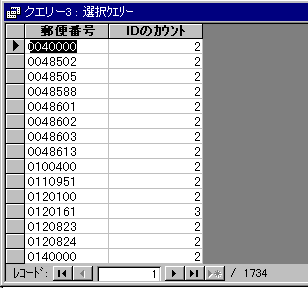
と、こんな感じ・・・。2回以上登場する郵便番号の一覧です。
うーん、けっこうありますねぇ・・・・。まあ、もともと郵便番号台帳みたいなものだったんでしょう。
住所と郵便番号が一対、というわけじゃなさそうです。
地区テーブルを開いてみましょう。ふつうは[ID]順に並んでますね。主キーだから。
これを一時的に[郵便番号]順に並べ替えてみます。ツールボタンの「AZ」を使えば昇順に並び変ります。
で、検索ツールボタン(青い印をつけた方)をクリックして、ダブってると思われる郵便番号を検索してみましょう。
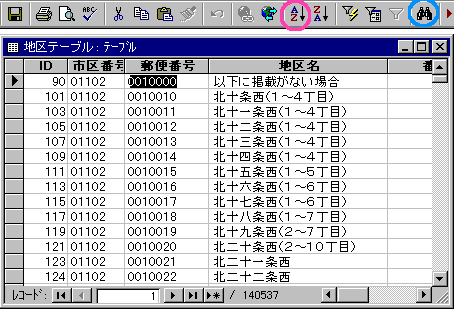
並べ替えをしているので、同じ郵便番号どうしまとまって表示されてますよね。
同じ郵便番号で異なる地区名のレコード、ずいぶんあるんですね。
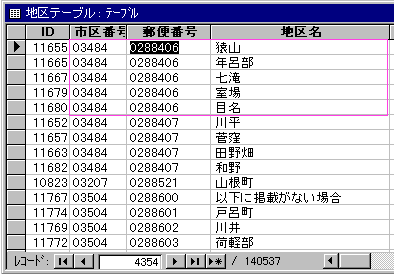
残念ながら、郵便番号自体をこのテーブルの中心として考えることはできないようです。
いろいろご覧いただきましたがいかがでしたでしょう。ひとつ処理を組み立てるにしても、やっぱりテーブルの設計は大事ですよね。
でも、これがなかなかむずかしいんだなぁ・・・。さいしょからピシッとした形のテーブル設計ができれば苦労はないですよね。
なので、ちょっと進んでは戻ってテーブルを見直す、みたいなやり取りをする覚悟で望んだ方が、最終的には使いやすいものが短時間にできることになると思います。
最初に適当に作ったテーブルの形を崩さないようにするためにいらん処理をいっぱい注ぎ込まないとならなくなっちゃうってことも、多々ありますからね・・・。
こいつは永遠のテーマです。
[郵便番号をまじめに FIN]